목차
0. wsl 설치 (window 한정)
1. git lfs 설치
2. llm 모델 선정 후 다운로드
3. vllm 설치
4. run
0. wsl 설치
vllm이 윈도우를 지원하지 않는 관계로 wsl 설치하여 ubuntu환경 세팅 필요
powershell 관리자 권한 실행
wsl --install
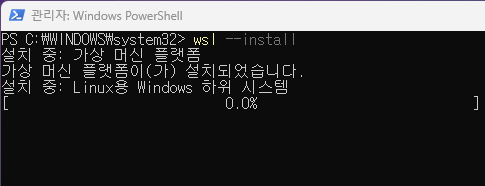
재부팅 후 다시 powershell을 켜고 wsl --install
설치 완료후 powershell ~ wsl 입력하면 ubuntu 환경으로 들어가진다.
wsl 최초 접속시 계정 비밀번호를 설정하는데 나중에 git lfs 설치할때 필요하니 메모
참조1: https://learn.microsoft.com/ko-kr/windows/wsl/install
1. git lfs 설치
git clone 명령어로 model을 받으면 용량이 큰 safetensor를 제대로 못 받아오는 경우가 있다. 이를 방지하기위해
step 1. git clone > safetensor를 제외하고 받은 뒤
step 2. git lfs pull > safetensor를 따로 받는다
따라서 git lfs를 사전에 설치.
wsl 내부에서 아래 커맨드 순서대로 실행 (sudo 권한이 필요하기때문에 앞서 설정한 계정 비밀번호 입력)
# 패키지 저장소 연결
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
# 패키지 설치
sudo apt-get install git-lfs이후 git lfs 입력하여 버전과 사용법 등이 뜨면 설치 완료.
참조2: https://github.com/git-lfs/git-lfs/blob/main/INSTALLING.md
2. llm 모델 선정 후 다운로드
사용 목적, 로컬PC 사양(주로 gpu vram) 고려하여 llm 선정
여기선 포스팅 목적, 8gb vram을 고려해 1.5B 모델
한동안 이슈였던 DeepSeek R1의 1.5B distillation
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B

다운로드 받을 디렉토리에서 커맨드 입력 (wsl 내부 디렉토리에 받는걸 추천)
아래와 같이 git clone 수행하면서 대용량 파일 제외하고 받는 커맨드 사용
# If you want to clone without large files ....
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
클론한 디렉토리를 확인해보면 weight에 해당하는 .safetensors 파일 크기가 1kb
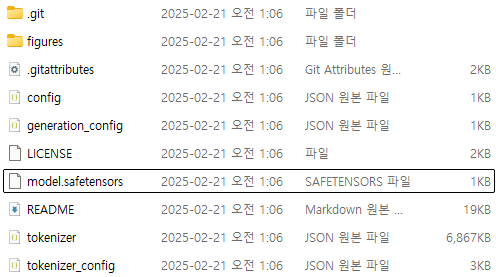
모델 디렉토리 내로 들어간 뒤 git lfs pull을 통해 model weight를 다시 받아줘야 한다.

이렇게 safetensor까지 받아주면 모델 준비 완료
3. vllm 설치
vllm에 대해 작성한 별도 포스트 참고
4. run
OpenAI-Compatible API Server 띄우기
일반적으로 사용하는 방식. 레퍼런스 자료들이 많은 OpenAI api와 호환도 가능.
[3. vllm 설치] 에서 세팅한 가상환경 내에서 커맨드 실행
python -m vllm.entrypoints.openai.api_server --model /home/jhjun/models/DeepSeek-R1-Distill-Qwen-1.5B/ --port 8008 --max-model-len 1024 --tensor-parallel-size 1
위 입력의 의미는
--model /home/jhjun/models/DeepSeek-R1-Distill-Qwen-1.5B/ : Deepseek distill 1.5B 모델의 경로
--port 8008 : 8008번 포트로 서빙
--max-model-len 1024 : 입력 토큰 1024로 제한
--tensor-parallel-size 1 : gpu 1개

잘 올라갔으니 8008번 포트로 request
from openai import OpenAI
llm = OpenAI(
api_key="EMPTY",
base_url="http://localhost:8008/v1",
)
chat_response = llm.chat.completions.create(
model="/home/jhjun/models/DeepSeek-R1-Distill-Qwen-1.5B/",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "who are you?"},
],
temperature=0.
)
print(chat_response.choices[0].message.content)출력

참조3: https://docs.vllm.ai/en/stable/getting_started/quickstart.html#quickstart-online
'프로젝트 > local LLM deploy' 카테고리의 다른 글
| vllm 설치하기 (0) | 2025.02.23 |
|---|